MTG Commander AI
A RAG pipeline turned 32,807 podcast transcript chunks into 41,790 structured insights, then Claude Sonnet cross-checked every one against real card text and deleted 5,236 it had invented.
Why this exists
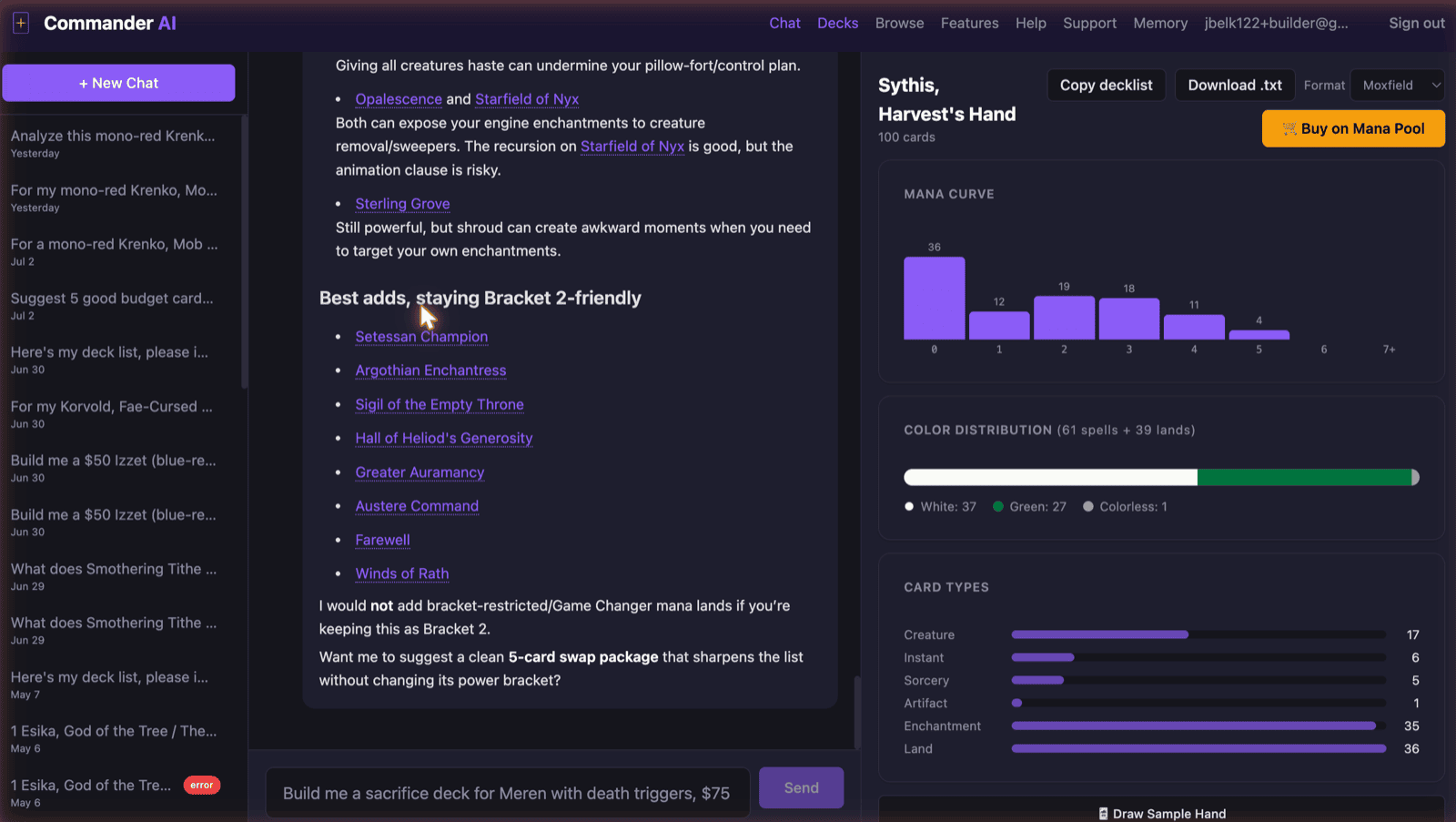
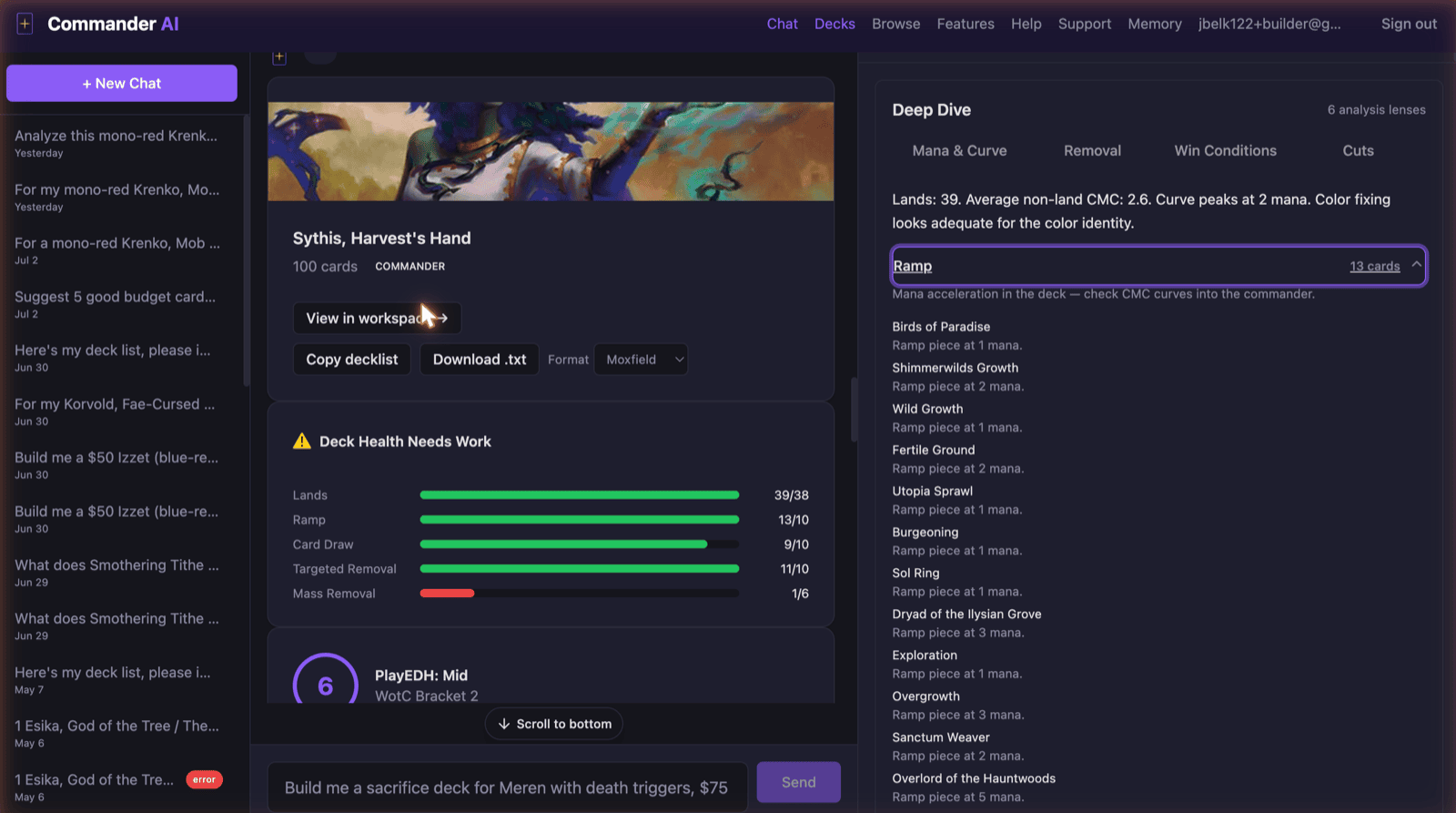
A friend of mine, Wes, was building a homebrew Magic: The Gathering cube by hand. He had 10 defined archetypes and a card list, but no easy way to check whether his black-green reanimator support was actually deep enough or just felt deep. Commander deckbuilding has the same problem at a bigger scale. EDHREC gives you popularity data, not the reasoning a good player would give you for why a specific card fits your specific 99. mtgcommander.ai is a conversational assistant that reads real card data (33K+ Scryfall cards) and real expert reasoning (transcript chunks from 10+ podcast and YouTube shows), builds full Commander decks against a stated budget and bracket, and hands the actual purchase off to Mana Pool through an affiliate link. It runs as a live, free product today, not a prototype, funded by 1 Patreon patron at $20/month plus Ko-fi tips instead of a paywall.
Architecture
Card data, podcast and YouTube transcripts, and cube or deck imports feed a Python pipeline that chunks, embeds, and extracts structured insights, validating every mechanic claim against the card’s own oracle text before anything is stored. All of it lives in 1 Supabase Postgres database with pgvector, alongside auth and conversation history, not a separate vector store. A FastMCP tool server exposes that knowledge base as discrete, individually callable tools (the same tools a raw MCP client like Claude Desktop could call directly), and a SvelteKit chat frontend running the Vercel AI SDK orchestrates those tools through phase-based routing informed by a real usage audit. The product is free forever, funded by optional Patreon support (1 patron at $20/month) and Ko-fi tips instead of a paywall, and when a user is ready to buy the deck, the purchase itself completes on Mana Pool through an affiliate link, not inside this app.
What shipped
By spec 164 the platform had grown from a favor for Wes’s cube into a real free product: a Mana Pool affiliate checkout handoff, a Patreon-synced Discord community, and a knowledge base that validates itself before storing anything new. The hallucination cleanup alone processed 33,040 insight-card pairs, deleted 5,236 confirmed hallucinations, and left the extraction pipeline validating every new insight against oracle text before storage, not just the backfill. The tool-routing audit replaced guesswork with 293 real tool calls across 50 conversations, consolidating or rerouting 12 tools that had 0 calls in the sample. All of these fixes came out of the same spec, plan, tasks, and research loop with Claude Code, not a rewrite from scratch.
The extraction pipeline still runs as a batch process, not real time. That’s deliberate: validating a new insight against a card’s oracle text before it ever reaches a user matters more than shipping it a few minutes faster.